
6月2日消息,近日,AMD发布了计算加速卡“Alveo V80”,专为内存密集型工作负载提供灵活的加速,也是AMD第一款大规模市场化的FPGA加速卡产品。
它有着丰富的应用领域和场景,比如基因组学、分子动力学、传感器处理等高性能计算,欺诈检测、公共事业、医疗分析、供应链分析等数据分析,风险分析、算法交易、Web3应用等金融科技,数据包监控、防火墙等网络安全,存储,推荐引擎、大语言模型等AI计算,等等。


简单地说,它和AMD Instinct这样的产品都属于计算加速器,但不是负责在算力上进行加速,而是专门用于解决大数据集计算负载中经常存在的内存以及网络瓶颈,打通整个计算链条。
这也是AMD的独特优势产品,更是其全栈计算解决方案中的重要一环。
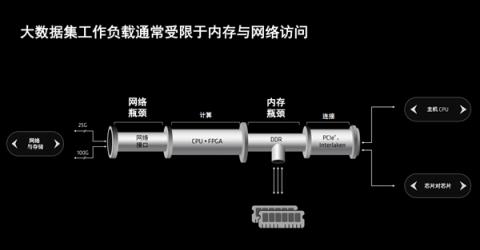
这是传统的大数据集工作负载处理流程示意图,可以看出有两个地方容易成为瓶颈。
一是内存,无论是DDR4还是DDR5,带宽其实都是有限的,无法和PCIe相媲美,经常无法满足CPU、FPGA等各种芯片、计算传输的需要。
二是网络,传统方案往往是固定网络接口与带宽,一旦需要超大规模数据传输,就可能满足不了。
另外,整个工作流程也缺乏全方面的安全防护。

AMD Alveo V80加速卡就是为解决这类问题而来。
首先将板载的独立内存升级为整合HBM,其优势就是超高带宽,又与主芯片紧密集成,已经在HPC/AI加速器中广泛应用。
其次是支持从10G到800G的广泛网络连接,可以按需选择、组合,满足灵活应变的计算。
另外就是全程都有安全连接,对于敏感应用是非常关键的。

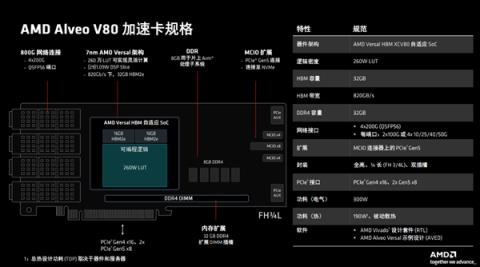
这就是AMD Alveo V80加速卡的整体设计与规格,全高、3/4长度的扩展卡形态,也就是高约111毫米、长约234毫米。
主芯片采用7nm工艺制造,是一颗Versal HBM XCV80自适应SoC,集成了多达260万个LUT可编程逻辑单元、10848个DSP计算逻辑单元,还整合封装了32GB HBM2E高带宽内存,带宽高达820GB/s。
如果需要,还可以通过板载的DDR4 DIMM标准插槽,再扩展最多32GB内存。
网络方面采用QSFP56光纤模块,支持最高800G带宽,可实时处理传入的海量数据,并支持4X200G,以及4X10G/25G/40G/50G等不同工作模式,能通过以太网扩展到数百个节点,组建计算集群。
同时内置400G加密引擎、600G以太网硬块,再加上FPGA的硬件灵活性,可以实现线速数据包检测,以及AI支持的异常检测,确保网络安全。
卡上还设置了MCIO扩展端口,可以直连NVMe存储,并完成板对板仿真开发工作。
系统连接总线支持一路PCIe 4.0 x16或者两路PCIe 5.0 x8。
整卡电气功耗300W,热设计功耗190W,可以采用被动散热,也可以根据元器件和服务器来定制热设计功耗水平。

Versal HBM自适应SoC芯片的整体架构图,可以看到两个Cortex-A72应用处理器核心、两个Cortex-R5F实时处理器核心、可编程逻辑引擎、DPS引擎等核心组件,其中DSP性能比上代提升了2-3倍。
它硬化了与基础设施的连接,包括DDR内存控制器、DMA PCIe控制器、可编程片上网络等,集成度更高,连接更方便。
此外就是网络部分,集成多个高带宽核心,包括一个100G以太网核心、一个600G以太网核心、一个600G Interlaken核心,以及一个400G加密引擎。

传统架构是固定的缓存层次,数据的读取和写入必须非常“规矩”,一旦有不规则的访问,就会大大降低效率。
自适应计算新架构则非常灵活,就是在计算附近分配内存,可以大大降低延迟、功耗,而且可以灵活适应自定义的数据类型和数据迁移。
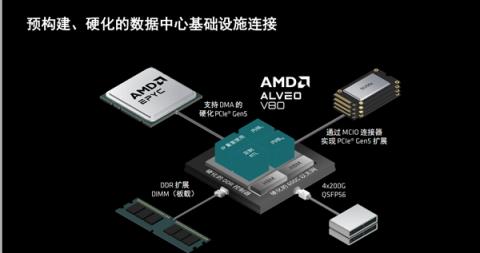
预构建硬化的数据中心基础设施连接,可以非常方便地连接板载扩展内存、以太网络、MCIO端口,以及高性能的EPYC处理器。

相比于传统的GPU加速器,Alveo V80这样的网络附接加速卡自然不是用来完全取代的,但在很多应用中也有自己独特的优势。
尤其是GPU加速卡都要与CPU连接,扩展数量存在很大的限制,网络附接加速卡就更灵活一些,包括低时延传入网络、绕开CPU与加速器之间的PCIe连接瓶颈、无需独立网卡,从而实现加速卡和计算密度的最大化。
同时,对于传入网络数据可以灵活管理,包括按需限速、在线加密、数据包监控等等。
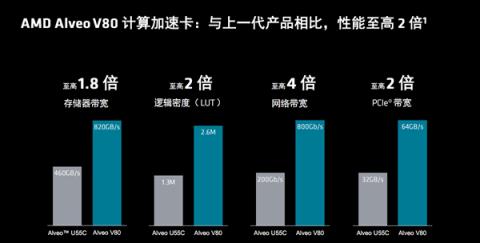
这是和上一代Alveo U55C的性能对比:
内存带宽提升至1.8倍,逻辑单元密度提升至2倍,网络带宽提升至4倍(200G变成800G),PCIe带宽提升至2倍(PCIe 4.0升级到PCIe 5.0)。

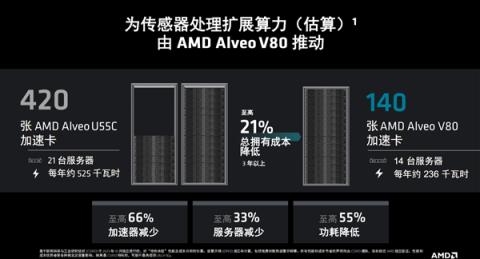
Alveo V80加速卡应用案例,澳大利亚国家级研究机构CSIRO(联邦科学与工业研究组织)参与建设的世界最大射电天文天线阵列,通过处理无线电波,研究早期宇宙及其演化,拥有多达13.1万个天线,持续传感器传输带宽高达15Tbps。
该阵列目前配备420块Alveo U55C加速卡,用于波束成形和相关器,需要占用21台服务器和4个机架空,已经逐渐无法满足越发复杂的负载需求。
为此,CSIRO升级到了Alveo V80,只需要140块加速卡、14台服务器,分别减少了2/3、1/3,性能提升了2-3倍,但同时功耗也降低了多达55%,三年TCO成本还可降低最多达21%。
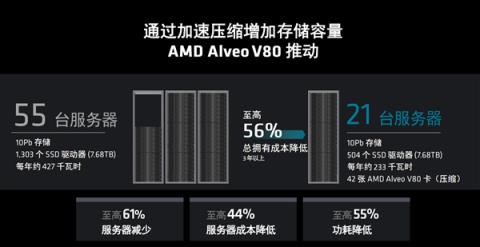
再比如具备压缩与数据分析功能的服务器存储节点,引入Alveo V80进行压缩,可以减少61%的服务器空间、44%的服务器成本、55%的功耗,三年TCO总成本可以节省多达56%。


还有网络安全、金融科技方面的用例,Alveo V80加速卡都可以带来更高的价值,这里就不展开了。

Alveo V80主要面向传统的FPGA软硬件开发人员,可以继续利用AMD Vivado设计套件、Alveo Versal示例设计(AVED),后者已可在GitHub上获取。

Alveo V80现已投入量产并出货上市,建议零售价9495美元,折合人民币近6.9万元。

本文转载于:快科技,仅供信息分享,无其他用途
本文内容由互联网用户自发贡献,该文观点仅代表作者本人。如发现本站有涉嫌抄袭侵权/违法违规的内容,请发送邮件至 97552693@qq.com 举报,一经查实,本站将立刻删除。本文链接:https://teaffka.com/n/43759.html
